I decided to make this tool GDC-transcript dragging my friend PeDev along with me. This tool is here to display a subtitle overlay on top of videos from the GDC YouTube channel, all transcribed using a tool called Whisper.
Beforehand, a quick brief about why.
Game Developers Conference 🔗
The Game Developers Conference is arguably the biggest game development knowledge base in the world. Without the need to attend the physical event, GDC Vault also offers all the talks and slides for just an annual fee of $599. Although the fee is certainly affordable for an established studio or developer, people who need it the most is probably those who just started and don’t have such luxury.
Thankfully, not only the Vault features some great talks free to access, there’s also the GDC YouTube channel featuring more than 1,700 videos.
Unfortunately, as I watched almost every video in the channel, I found some issues manifest:
- Some video suffers from bad audio quality or mixing, such as this Portal talk (please lower volume before clicking).
- Some speakers are heavily accented, probably only native level English speaker and understand them easily, such as this Assassin’s Creed Origins talk.
- Or both, such as this FFXV talk.
All three of them are great talks that I highly recommend, but the problems mentioned above makes it hard for everyone to consume.
This is where the transcription comes in.
OpenAI’s Whisper 🔗
Frank Chao, friend of the discord server IGDShare, posted a video on our resource dumping channel, in which introduced an offline transcription tool called Whisper.
This open source project built by OpenAI is lightyears above that of Google’s. Not only does it can recognize game/game development related keywords easily, it is also relatively unaffected by the bad audio and heavy accent, so I quickly figure it would be a great tool to transcribe GDC’s video. Though it also has some traits of generative AI which means it might make things up in some special cases.
All in all, the pros outweigh the cons significantly, so I decided to transcribe all publicly available videos on the GDC YouTube channel. Though instead of using Whisper directly, I instead opted for a variant called WhipserX.
WhisperX 🔗
Whisper is great, but not without some substantial issues:
- The largest model requires quite some time to transcribe.
- The subtitle transcribed seems to have a minimum duration of 1 second, which leads to less than ideal viewing experience.
After some searching, I found this version called Whisper X that had relatively better results and the cost of slightly longer transcription duration. The improved performance is mostly because of two additions:
- Voice Activity Detection, a process to identify parts that have active voice.
- Forced Alignment, a process that matches the text back to its most probable position.
Both combined resulting in extremely desirable results. Though not without its own issues, but this is by far the best choice.
Run Transcription with Google Colab 🔗
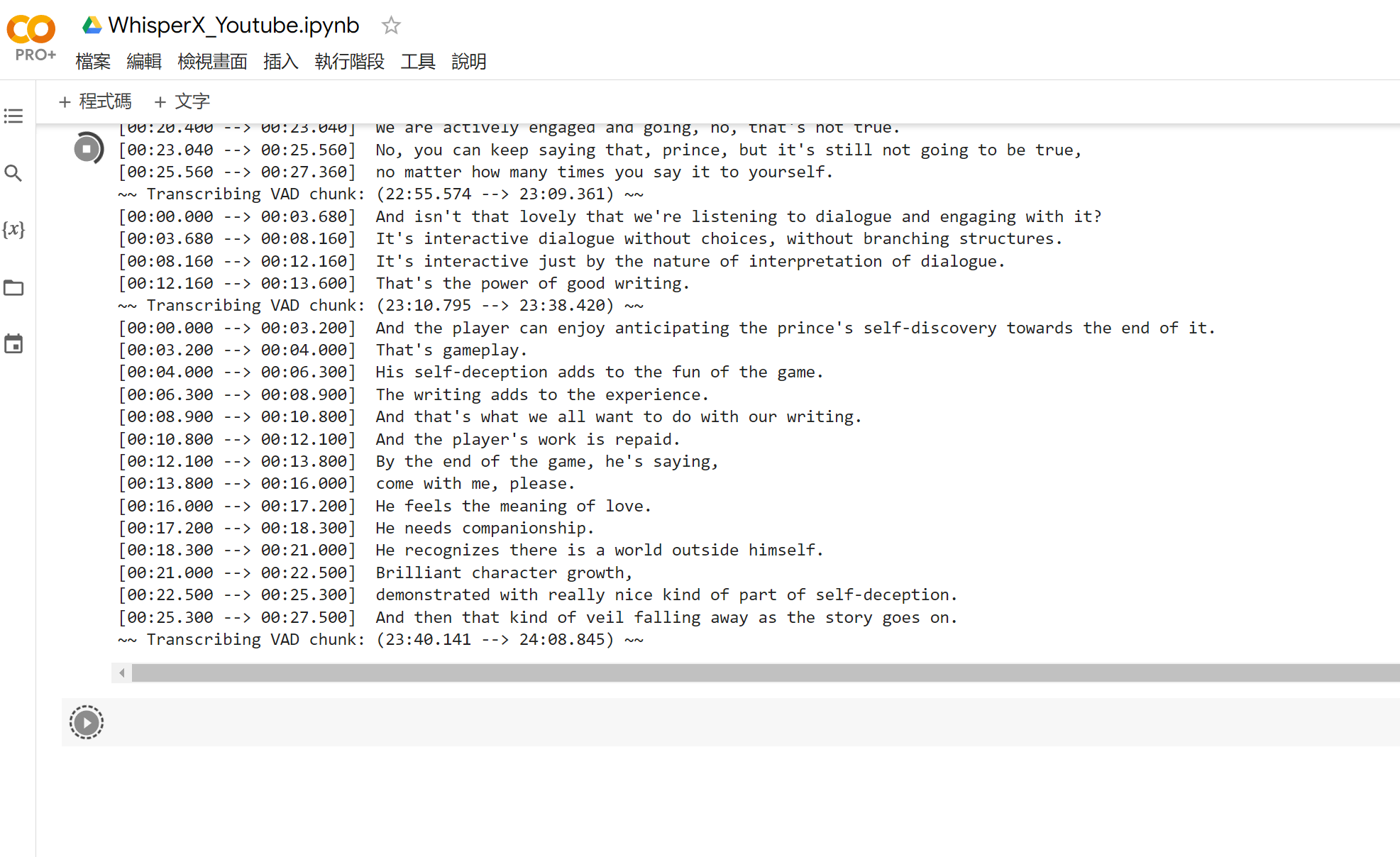
With my rig sporting an NVIDIA RTX3080, Whisper runs quite smoothly, though I ended up transcribing on Google Colab using Jupyter Notebook for some reasons:
- I’m still supposed to make my own game, so I’m not about to let Whisper take up my resources.
- It’s easy to run multiple notebooks on Google Colab.
- Python related environment problems are hard to tackle and takes up a lot of space.
The last one especially took me and PeDev about a full day to find the ideal setup, which in the end is to just use Google Colab’s clean environment so the setup will be less of a hassle. If anyone is interested, this Notebook is what we used for the final transcription.
The Tool Site 🔗
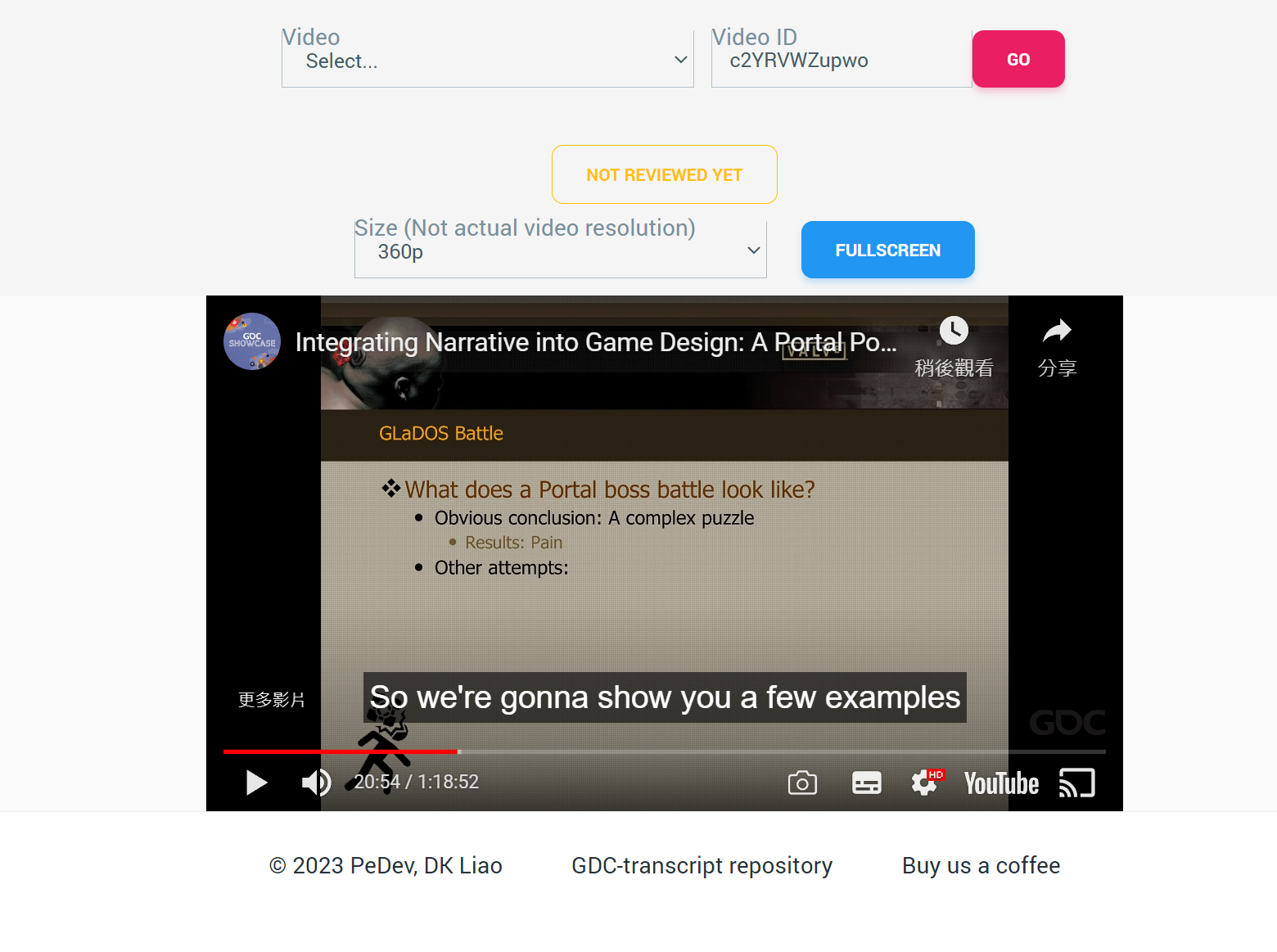
For the site, I just want to make it simple and clean. Find an UI framework, have a place to input the video ID, and then show the video and subtitle. Simple as that!
I asked Jason for UI framework recommendation, landed on Material Tailwind. And boy I don’t miss the days I struggled with CSS in my youth.

For subtitle overlay, PeDev found this youtube.external.subtitle. In order to just use SRT files, subtitles-parser is used for parsing.
Clearly the ergonomics isn’t good enough, so we then added:
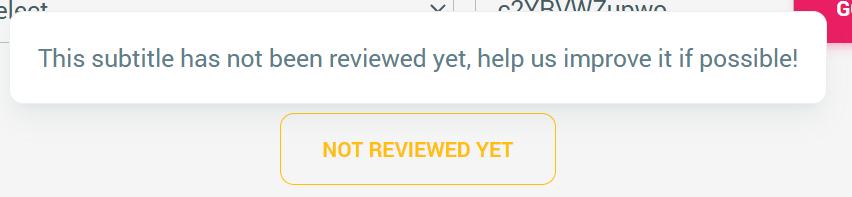
- A clear indication of the subtitle being reviewed or not.
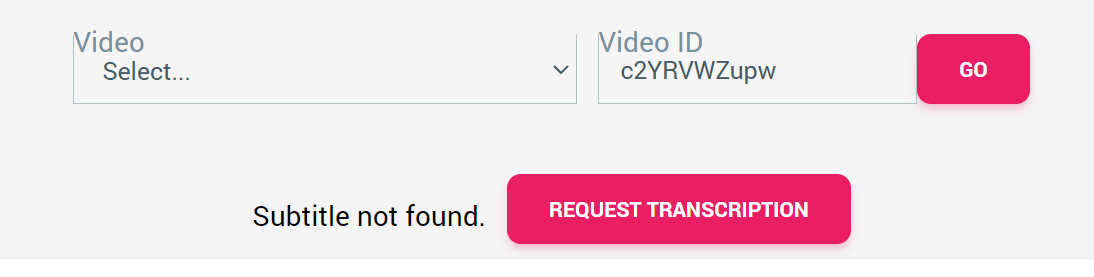
- An easy one button solution to request transcription.
- Extra measures to scale the video.
- Separate fullscreen video logic for youtube.external.subtitle can’t just recognize YouTube embedded video’s fullscreen action.
So that’s it, the site is done!
The Open Source Project 🔗
Although I consider myself pretty fast in translation, the sheer amount of videos just isn’t possible to be handled on my own. With the deployment of Github Repository GDC-transcript I hope to solve the rest of the problems with developers around the globe. Plus Github Page for the tool page is really easy to use.
I’m definitely getting ahead of myself here but in order to have a smooth workflow, we went through some extra steps:
- Setting up New Issue template for easy requesting, also automates the video ID assignment if pressing the button on the site.
- Setting up a thorough Readme to explain the ins and outs of this project, and hopefully GDC won’t be suing me.
- Having a clear Contributing Guide and Pull Request template so that future contributors can help us easily without the need to ask lots of questions first.
In order to let the frontend of the site access information more easily, PeDev wrote a metadata generator alongside the site publishing Github Action, me on the other hand wrote an Action to quickly generate transcripts from SRTs and perform pull request on its own.
Conclusion 🔗
I would love to go the extra mile and try to have GPT4 perform summary and potentially translate to other languages, but especially the translation parts still doesn’t serve as a great starting point especially coming from a not yet proof read subtitle. This is as far as we can get for now. I hope this small project can help some developers in need regardless of the audience size.
Also although I think this is perfectly within the realm of fair use, but GDC is also rightfully so to have the repository removed since they technically own the content. If that’s what happens, at least we had a good run.
If you have any questions or suggestions, feel free to submit an Issue on Github or contact me on Twitter. Thanks for reading!