總之因為一些因素,拖著小峰跟我一起淌這個渾水,做出了一個小網站 GDC-transcript。這個網站有我們轉錄好的 GDC YouTube 頻道所有公開影片(根據實際貼文日期可能還只有最熱門的前幾百個)的英文逐字稿。
雖然不是中文的,也還沒有經過檢驗,反過來說還希望仰賴社群力量來完成檢驗與潛在翻譯,但或許已經足夠讓一些原本不方便觀看影片的人能順利觀看了。
以下會介紹一下 GDC 以及整個專案的過程。
Game Developers Conference 🔗
Game Developers Conference,簡稱 GDC,是全球最大的遊戲開發者盛事。一年一度在舊金山舉辦的這場活動應該是遊戲從業者最大的知識庫,除了聆聽講座、參加工作坊以外,實體活動參與者通常也是藉此機會來擴張人脈。
只是要看講座的話,GDC Vault裡面存有所有內容,年費 599 美金的花費至少也是可以存取到產業最新的知識,不過大概不是所有人都這麼有餘裕。但至少 GDC YouTube 頻道隨時間也免費公開了 1700 多支的影片,其中也確實囊括了不少重要性跟實用性偏高的講座。
不過隨著自己觀看了不少影片,也意識到果然還是有一些可惜之處:
- 有些影片的錄音品質不太好,聽起來很痛苦,像是《Portal》的演講(爆音注意)
- 有些開發者的口音偏重,大概只有母語級英文使用者或與演講者同源的人才能順利聽懂,例如說關於《刺客教條:起源》AI 系統的演講
- 又或者是兩個兼具,例如《FFXV》AI 系統的演講
這三部影片的內容都很棒,但是都因為一些額外問題而讓這些內容難以被了解。所以內心一直惦記著要找個機會試著做 GDC 的中文共筆,希望可以整理一些自己覺得很有用的影片讓大家參考。
共筆雖然還沒能準備,但倒是先因為一些因素而做出了 GDC YouTube 頻道公開影片的完整逐字稿。
緣起 🔗
總之海龜在 IGDS Discord 伺服器上貼了一部影片,介紹名為 Whisper 的影片逐字稿生成系統。
Whipser 是由 OpenAI 推出的開源專案,雖然我一項對歐美主導開發的逐字稿生成系統有一些意見(例如說句子結構通常很爛),但反正研究一下也不會花太多時間吧,就簡單嘗試了一下。經過簡單的測試後,意識到幾件事情:
- Whisper 可以有效地紀錄下來混用的語言,或以我測試的例子來說是中文與英文的混用
- Whisper 的背後訓練的資料集涵蓋知識量相當高,有許多專有名詞都能被順利辨識出來
因此意外地是個真的品質很高的逐字稿生成工具。當然也不是說沒缺點,例如說:
- 骨幹應該也是文字生成式 AI,所以有一定機率會產出睜眼說瞎話的內容
- 文字結構還是不太好看
但無論如何已經是省下的功夫遠大於額外調整需要的功夫了,值得一戰。搭配著對 GDC 中文共筆的惦記,於是就決定簡單燒一點 Google Colab 費用來跑逐字稿轉錄,順便把小峰拖下水跟我一起研究。
改用 WhisperX 🔗
Whisper 雖然很強大,但姑且還是有幾個顯著的問題:
- 資料集最大的模型,配對時間算是很長
- 配對出來的字幕似乎有最小一秒的間隔限制,顯示精準度算差
經過一些搜索之後,最後找出了一個改版 Whisper X 有相對好的表現。表現的差異主要源於兩個額外步驟:
- Voice Activity Detection,通常簡稱 VAD,是個偵測哪段音訊有人講話的步驟
- Forced Alignment,是個將產生出來的字幕範圍進行變形(拉長、縮短、位移),配對到最理想位置的步驟
加上了這兩個步驟的 WhisperX 雖然不是完全無敵,但已經將 Whisper 的潛在可用性發揮到極致。
使用 Google Colab 執行 🔗
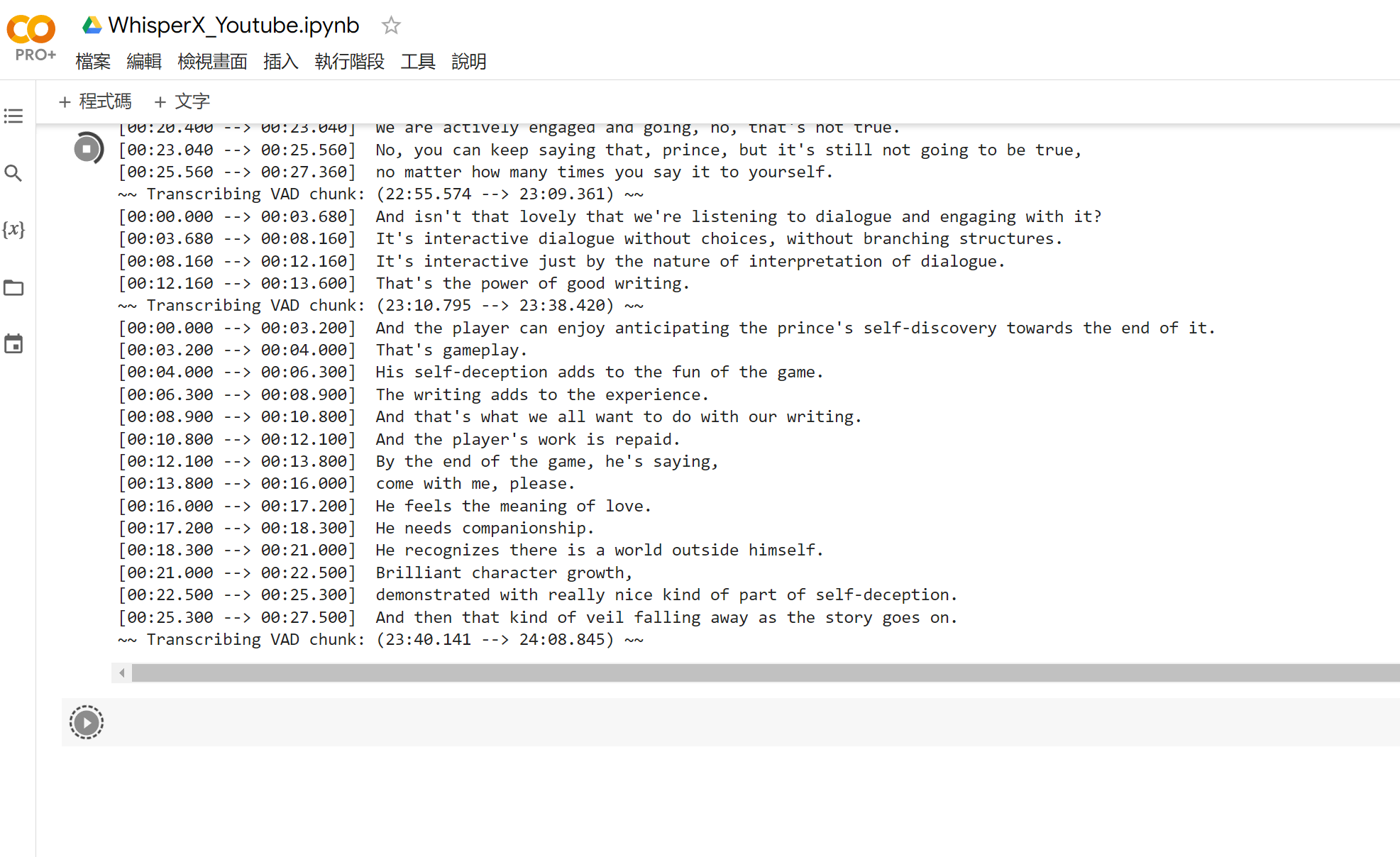
雖然我這邊本機的 NVIDIA RTX3080 執行 Whisper 起來並不慢,但後來決定做成 Jupyter Notebook 形式放在 Google Colab 上,有幾個理由:
- 我理論上本業應該要繼續開發遊戲,不能分散 GPU 資源(雖然還是為了這個專案荒廢了幾天)
- Colab 可以輕鬆多開
- Python 相關環境問題本機處理起來很難應對又佔空間
尤其最後一點的環境問題,讓我跟小峰在第二天幾乎都卡死在研究各種不同 Whisper 改版怎麼正確執行。後來意識到 WhisperX 可以輕鬆在 Google Colab 執行後就直接使用無懸念。有興趣的人可以用這張 Notebook 執行自己需要的字幕逐字稿生成。
工具網站 🔗
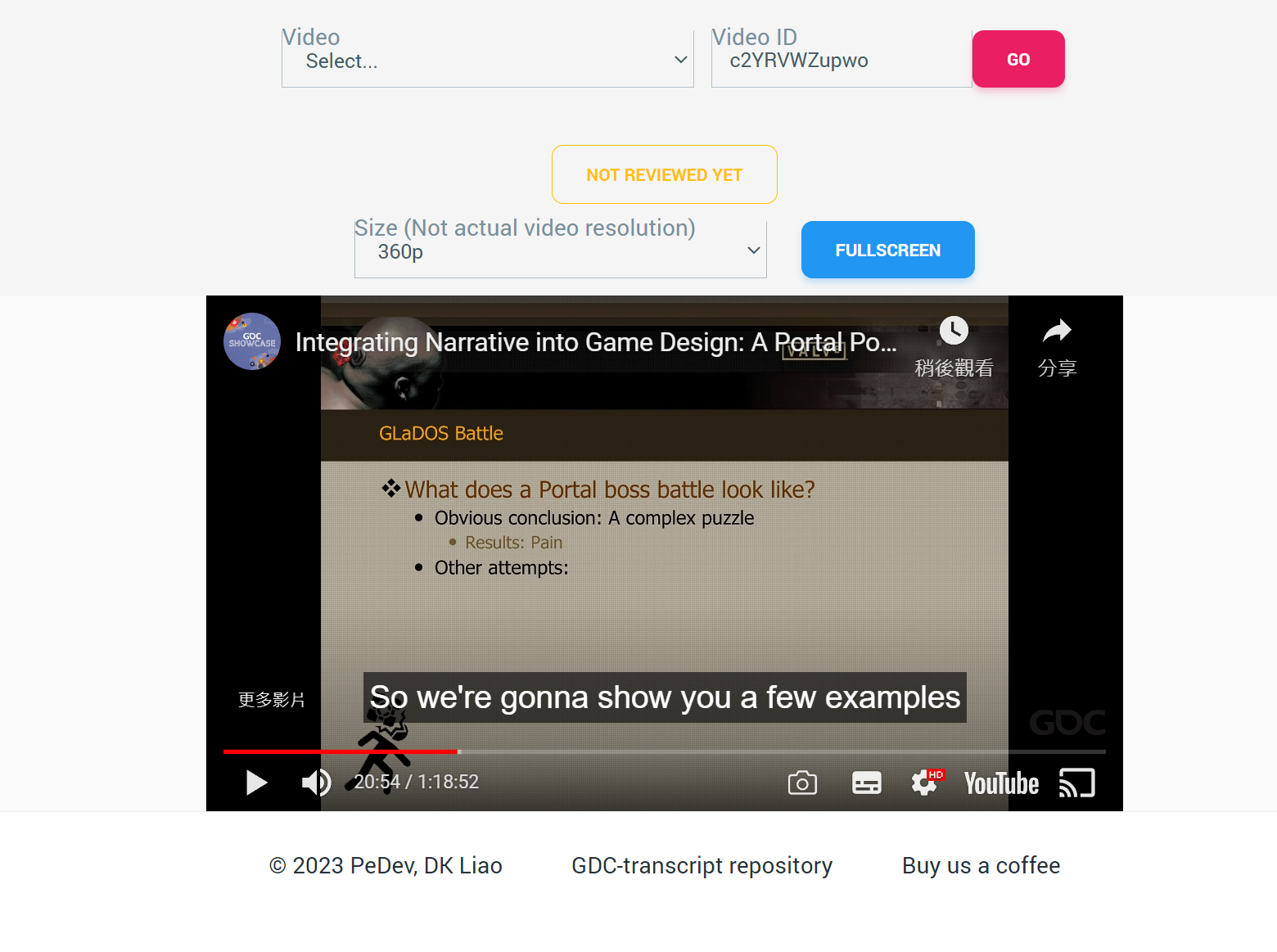
工具網站本身走簡潔至上,基本上就是找個 UI 模板套,給個位置輸入影片 ID,同步顯示 YouTube 影片跟字幕,收工!
UI 模板隨口問了一下小白,選用了 Material Tailwind,一邊使用又一邊想起小時候操作 CSS 的惡夢。

影片字幕的顯示找到了 youtube.external.subtitle,為了方便性字幕格式使用 srt 原檔直上,所以還需要可以 parse 的工具,使用了 subtitles-parser。
當然隨著設計也一邊意識到有一些額外問題,慢慢補上了一些設計:
- 標註清楚字幕是否經過校閱
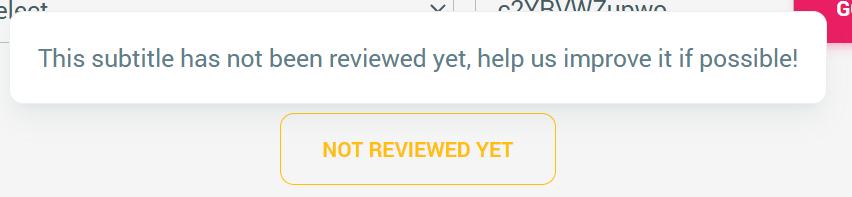
- 提示使用者可以請求字幕的生成
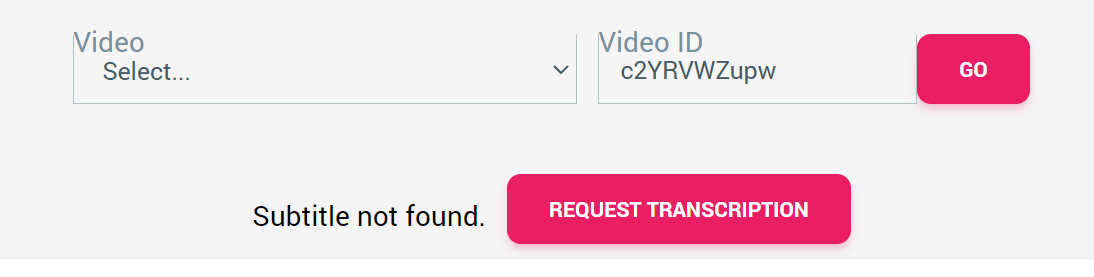
- 加入額外的影片大小修改方式
- 另外刻一個顯示全螢幕影片的邏輯(youtube.external.subtitle 沒辦法直接吃 YouTube 內嵌的全螢幕邏輯)
大概這樣子,網站就八七成完成了。
開源專案設置 🔗
就算我自認為自己在翻譯工程上處理速度很快,面對上千部影片還是不太可能自己處理,因此很快就定調要以開源專案的方式推行,希望靠社群的力量可以拚下最後一哩路。總之在 Github 上開了 GDC-transcript 專案,順便使用 Github Page 來部署工具實際的網站。
為了能順暢應對社群跟專案的推進,我跟小峰還做了很多額外處理,例如:
- 設立新增 Issue 的模板,幫助使用者填答,也在網站請求新影片字幕時直接導引填入 Video ID
- 設立完整的 Readme 解釋清楚整個專案的性質,也希望 GDC 不要跑來告我
- 寫清楚 Contributing Guide 跟設立 Pull Request 模板,幫助未來要貢獻校閱的人一點指引
為了讓前端可以更輕易取得一些資訊,而不需要手動分析專案狀況,小峰寫了一個對特定分支更新後會自動生成 metadata 並且發佈 Github Page 的 Action;此外身為井底之蛙的我,進了 Sigono 後才知道存在的 Github Action,也寫了一些工具來自動將 srt 字幕檔轉換為格式完整的 txt 逐字稿。
結語 🔗
總之對中文社群來說很抱歉還只能走第一步,有一個至少可用程度高一點的英文逐字稿字幕。原本想要仰賴一些同樣的系統,甚至提交給 GPT4 去進行進一步的翻譯,但目前測試起來品質都相當微妙,也十分費時而最終只能暫時作罷。
這次的小專案希望可以至少提供一些幫助,而且或許有機會對整體國際非英文母語遊戲開發者都產生貢獻,稍稍感到有點期待(GDC 不會跑來弄我為前提的話啦)。
有什麼對專案的建議都可以在 Github 上提出!